
2.7 为什么 0.1 + 0.2 不等于 0.3?
为什么负数要用补码表示?
接不知道你有没有想过,为什么计算机要用补码的方式来表示负数?在回答这个问题前,我们假设不用补码的方式来表示负数,而只是把最高位的符号标志位变为 1 表示负数,如下图过程:

如果采用这种方式来表示负数的二进制的话,试想一下 -2 + 1 的运算过程,如下图:
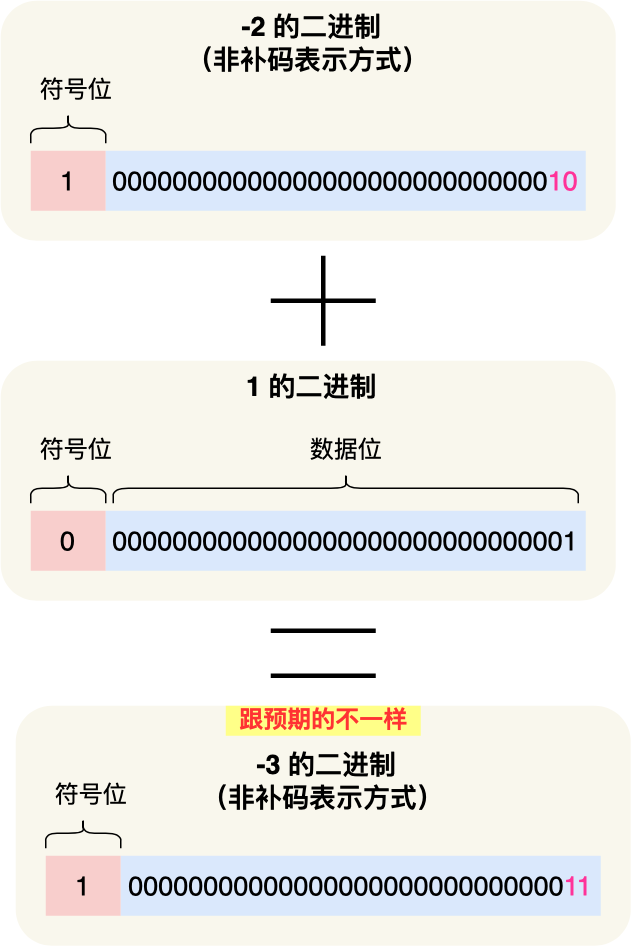
按道理,-2 + 1 = -1,但是上面的运算过程中得到结果却是 -3,所可以发现,这种负数的表示方式是不能用常规的加法来计算了,就需要特殊处理,要先判断数字是否为负数,如果是负数就要把加法操作变成减法操作才可以得到正确对结果。
因此如果负数不是使用补码的方式表示,则在做基本对加减法运算的时候,还需要多一步操作来判断是否为负数,如果为负数,还得把加法反转成减法,或者把减法反转成加法,这就非常不好了,毕竟加减法运算在计算机里是很常使用的,所以为了性能考虑,应该要尽量简化这个运算过程。
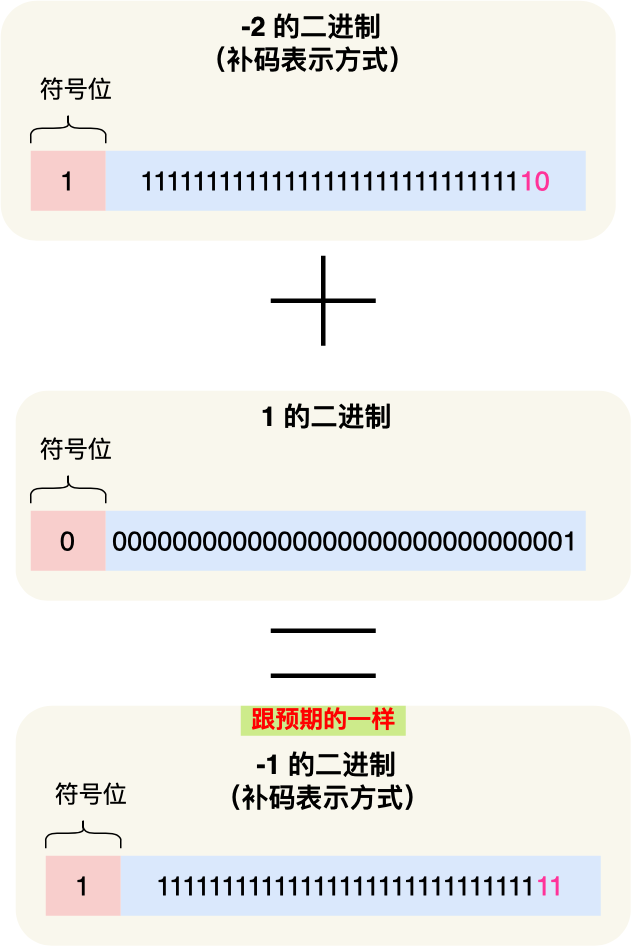
而用了补码的表示方式,对于负数的加减法操作,实际上是和正数加减法操作一样的。
十进制与二进制的转换
十进制整数转二进制使用的是「除 2 取余法」。
十进制小数使用的是「乘 2 取整法」。将十进制中的小数部分乘以 2 作为二进制的一位,然后继续取小数部分乘以 2 作为下一位,直到不存在小数为止。
如果我们把 0.1 转换成二进制,过程如下:
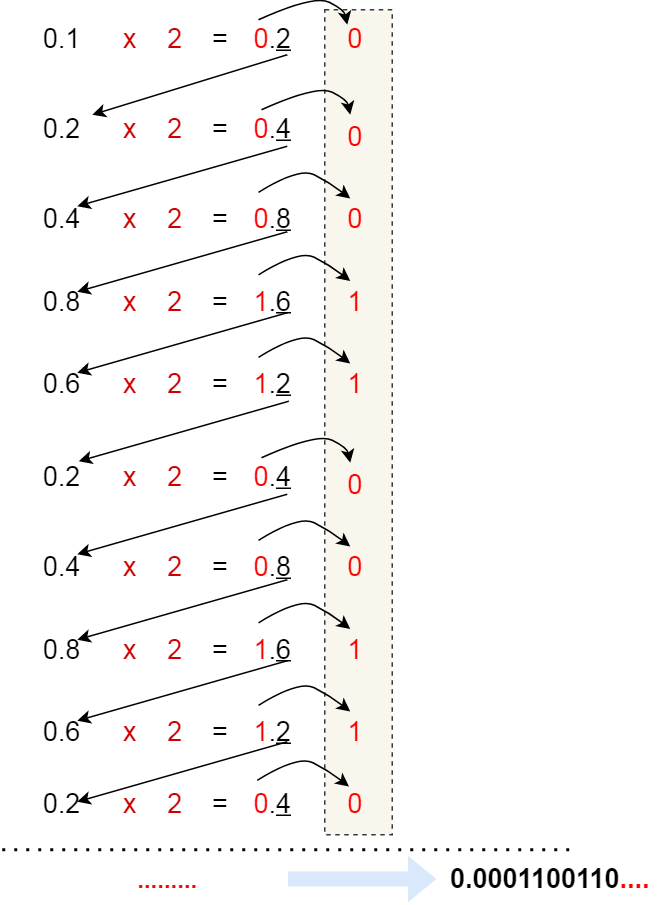
可以发现,0.1 的二进制表示是无限循环的。
由于计算机的资源是有限的,所以是没办法用二进制精确的表示 0.1,只能用「近似值」来表示,就是在有限的精度情况下,最大化接近 0.1 的二进制数,于是就会造成精度缺失的情况。
对于二进制小数转十进制时,需要注意一点,小数点后面的指数幂是负数。
比如,二进制 0.1 转成十进制就是 2^(-1),也就是十进制 0.5,二进制 0.01 转成十进制就是 2^-2,也就是十进制 0.25,以此类推。
计算机是怎么存小数的?
计算机存储小数的采用的是浮点数,名字里的「浮点」表示小数点是可以浮动的。
比如 1000.101 这个二进制数,可以表示成 1.000101 x 2^3,类似于数学上的科学记数法。
现在绝大多数计算机使用的浮点数,一般采用的是 IEEE 制定的国际标准,这种标准形式如下图:

这三个重要部分的意义如下:
符号位:表示数字是正数还是负数,为 0 表示正数,为 1 表示负数;
指数位:指定了小数点在数据中的位置,指数可以是负数,也可以是正数,指数位的长度越长则数值的表达范围就越大;
尾数位:小数点右侧的数字,也就是小数部分,比如二进制 1.0011 x 2^(-2),尾数部分就是 0011,而且尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
double 的尾数部分是 52 位,float 的尾数部分是 23 位,由于同时都带有一个固定隐含位(前置的1),所以 double 有 53 个二进制有效位,float 有 24 个二进制有效位,所以所以它们的精度在十进制中分别是
log10(2^53)约等于15.95和log10(2^24)约等于7.22位,因此 double 的有效数字是15~16位,float 的有效数字是7~8位,这些有效位是包含整数部分和小数部分;double 的指数部分是 11 位,而 float 的指数位是 8 位,意味着 double 相比 float 能表示更大的数值范围;
IEEE 标准规定,二进制浮点数的小数点左侧只能有 1 位,并且还只能是 1,既然这一位永远都是 1,那就可以不用存起来了。
于是就让 23 位尾数只存储小数部分,然后在计算时会自动把这个 1 加上,这样就可以节约 1 位的空间,尾数就能多存一位小数,相应的精度就更高了一点。
0.1 + 0.2 == 0.3 ?
这主要是因为有的小数无法可以用「完整」的二进制来表示,所以计算机里只能采用近似数的方式来保存,那两个近似数相加,得到的必然也是一个近似数。