
2.3 如何写出让 CPU 跑得更快的代码?
CPU Cache 的数据结构和读取过程是什么样的?
我们先简单了解下 CPU Cache 的结构,CPU Cache 是由很多个 Cache Line 组成的,Cache Line 是 CPU 从内存读取数据的基本单位,而 Cache Line 是由各种标志(Tag)+ 数据块(Data Block)组成,你可以在下图清晰的看到:
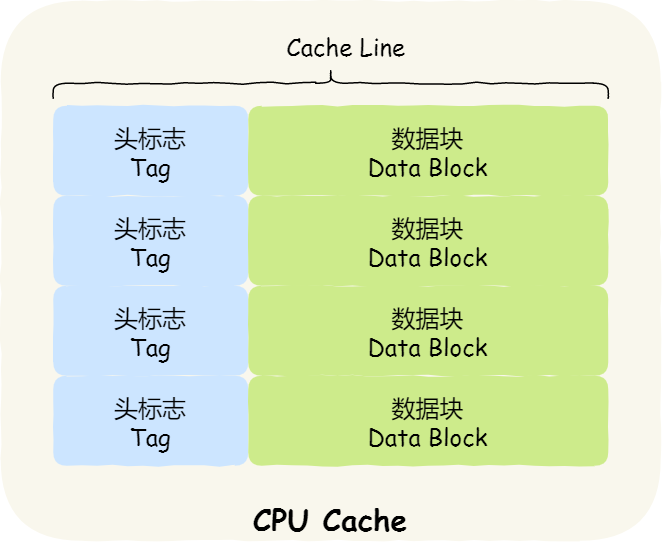
CPU Cache 的数据是从内存中读取过来的,它是以一小块一小块读取数据的,称为 Cache Line(缓存块)。
比如,有一个 int array[100] 的数组,当载入 array[0] 时,由于这个数组元素的大小在内存只占 4 字节,不足 64 字节,CPU 就会顺序加载数组元素到 array[15],意味着 array[0]~array[15] 数组元素都会被缓存在 CPU Cache 中了(空间局限性)。
事实上,CPU 读取数据的时候,无论数据是否存放到 Cache 中,CPU 都是先访问 Cache,只有当 Cache 中找不到数据时,才会去访问内存,并把内存中的数据读入到 Cache 中,CPU 再从 CPU Cache 读取数据。
直接映射 Cache :就是把内存块的地址始终「映射」在一个 CPU Cache Line(缓存块)的地址,至于映射关系实现方式,则是使用「取模运算」,取模运算的结果就是内存块地址对应的 CPU Cache Line(缓存块)的地址。那么就会出现多块内存对应同一个缓存块。
因此,为了区别不同的内存块,在对应的 CPU Cache Line 中我们还会存储一个组标记(Tag)。这个组标记会记录当前 CPU Cache Line 中存储的数据对应的内存块,我们可以用这个组标记来区分不同的内存块。
除了组标记信息外,CPU Cache Line 还有两个信息:
- 一个是,从内存加载过来的实际存放数据(Data)。
- 另一个是,有效位(Valid bit),它是用来标记对应的 CPU Cache Line 中的数据是否是有效的,如果有效位是 0,无论 CPU Cache Line 中是否有数据,CPU 都会直接访问内存,重新加载数据。
CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Cache Line 中的整个数据块,而是通过偏移量(Offset)读取 CPU 所需要的一个数据片段,这样的数据统称为一个字(Word)。
因此,一个内存的访问地址,包括组标记、CPU Cache Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。而对于 CPU Cache 里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。
如果内存中的数据已经在 CPU Cahe 中了,那 CPU 访问一个内存地址的时候,会经历这 4 个步骤:
- 根据内存地址中索引信息,计算在 CPU Cahe 中的索引,也就是找出对应的 CPU Cache Line 的地址;
- 找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
- 对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
- 根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
如何写出让 CPU 跑得更快的代码?
提高 CPU 缓存命中率。
如何提升数据缓存的命中率?
因此,遇到这种遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升:即按照数据在内存中排列顺序访问数据,不要随机访问会更快
如何提升指令缓存的命中率?
对于数组而言,觉得先遍历再排序速度快,还是先排序再遍历速度快呢?
CPU 有分支预测器。对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
当数组中的元素是随机的,分支预测就无法有效工作,而当数组元素都是是顺序的,分支预测器会动态地根据历史命中数据对未来进行预测,这样命中率就会很高。
因此,先排序再遍历速度会更快,这是因为排序之后,数字是从小到大的,那么前几次循环命中 if < 50 的次数会比较多,于是分支预测就会缓存 if 里的 array[i] = 0 指令到 Cache 中,后续 CPU 执行该指令就只需要从 Cache 读取就好了。
如何提升多核 CPU 的缓存命中率?
在单核 CPU,虽然只能执行一个线程,但是操作系统给每个线程分配了一个时间片,时间片用完了,就调度下一个线程,于是各个线程就按时间片交替地占用 CPU,从宏观上看起来各个线程同时在执行。
而现代 CPU 都是多核心的,线程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果线程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。