
TiDB - 分布式NewSQL数据库
TiDB是一个开源的分布式NewSQL数据库,支持水平扩展、强一致性事务和MySQL协议兼容。
tidb 的主键 id 不建议自增
tidb 是一款分布式数据库,作为 mysql 分库分表场景下的替代产品,可以更好的对数据进行分片。
它通过引入Range的概念进行数据表分片,比如第一个分片表的 id 在 0~2kw,第二个分片表的 id 在 2kw~4kw。这其实就是根据 id 范围进行数据库分表。
它的语法几乎跟 mysql 一致,用起来大部分时候是无感的。
但跟 mysql 有一点很不一样的就是,mysql 建议 id 自增,但tidb 却建议使用随机的 uuid。原因是如果 id 自增的话,根据范围分片的规则,一段时间内生成的 id 几乎都会落到同一个分片上,比如下图,从3kw开始的自增 uuid,几乎都落到range 1这个分片中,而其他表却几乎不会有写入,性能没有被利用起来。出现一表有难,多表围观的场面,这种情况又叫写热点问题。
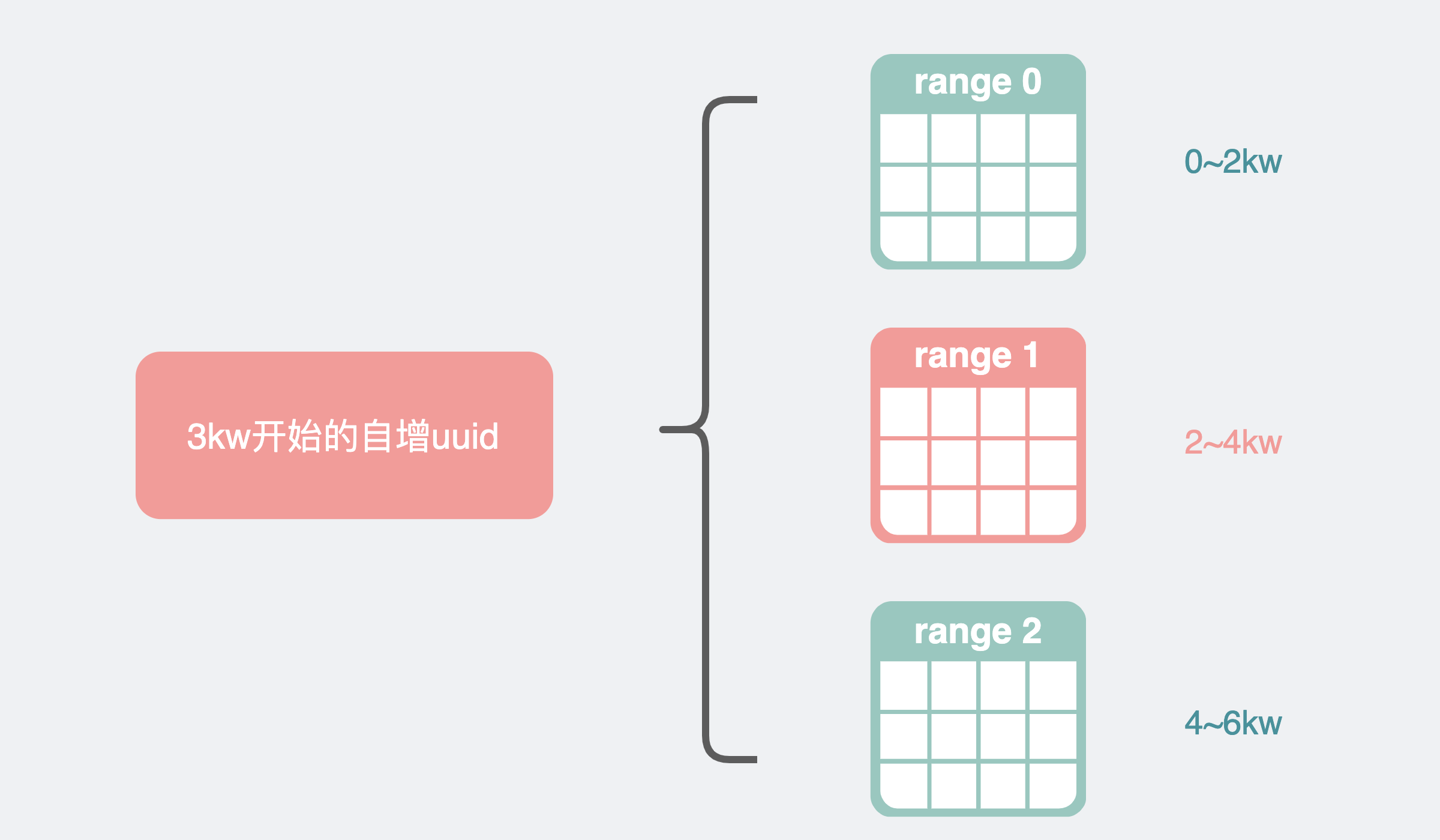
所以为了充分的利用多个分表的写入能力,tidb 建议我们写入时使用随机 id,这样数据就能被均匀分散到多个分片中。
📋 核心概念
TiDB架构
TiDB采用计算与存储分离的架构,主要组件包括:
- TiDB Server: 无状态的SQL层,负责处理SQL请求
- PD (Placement Driver): 集群元信息管理和调度
- TiKV: 分布式KV存储引擎,存储实际数据
- TiFlash: 列式存储引擎,用于OLAP查询
🎯 核心特性
1. 水平扩展能力
sql
-- TiDB支持在线水平扩展
-- 添加TiKV节点自动实现容量扩展
-- 添加TiDB Server节点提升查询并发能力
-- 查看集群拓扑
SHOW STATS_META;
-- 查看Region分布
SHOW TABLE t1 REGIONS;2. 强一致性事务
sql
-- TiDB支持ACID事务,默认隔离级别为可重复读
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
-- 支持乐观事务和悲观事务
SET SESSION tidb_txn_mode = 'pessimistic';3. MySQL兼容性
sql
-- TiDB兼容MySQL 5.7协议和语法
-- 可以使用MySQL客户端直接连接
-- 支持大部分MySQL语法
CREATE TABLE users (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_username (username)
) ENGINE=InnoDB;
-- 支持MySQL函数
SELECT COUNT(*), DATE_FORMAT(created_at, '%Y-%m') as month
FROM users
GROUP BY month;📊 TiDB vs 传统数据库对比
TiDB vs MySQL
| 特性 | TiDB | MySQL |
|---|---|---|
| 扩展性 | 水平扩展,理论无上限 | 垂直扩展,受单机限制 |
| 高可用 | 自动故障转移,Multi-Raft | 需要额外HA方案(MHA、MGR等) |
| 事务 | 分布式事务,强一致性 | 单机事务 |
| 容量 | PB级 | TB级(分库分表) |
| SQL兼容 | 兼容MySQL 5.7 | 完全兼容 |
| OLAP性能 | TiFlash列存支持 | 需要额外OLAP引擎 |
| 分片 | 自动分片,透明 | 需要手动分库分表 |
| 运维复杂度 | 分布式系统,较复杂 | 单机简单,分片复杂 |
TiDB vs PostgreSQL
| 特性 | TiDB | PostgreSQL |
|---|---|---|
| 扩展性 | 原生分布式 | Citus扩展或分片 |
| JSON支持 | 基础支持 | 强大的JSONB |
| GIS支持 | 基础支持 | PostGIS功能完善 |
| 窗口函数 | 支持 | 完全支持 |
| 全文搜索 | 基础支持 | 内置全文搜索 |
| 生态 | 发展中 | 成熟丰富 |
TiDB vs MongoDB
| 特性 | TiDB | MongoDB |
|---|---|---|
| 数据模型 | 关系型(表) | 文档型(JSON) |
| 查询语言 | SQL | MongoDB Query Language |
| 事务 | ACID,分布式事务 | ACID,多文档事务 |
| Schema | 强Schema | 灵活Schema |
| Join性能 | 原生支持 | 受限,性能较差 |
| 写入性能 | 中等 | 高 |
| 适用场景 | 结构化数据,复杂查询 | 半结构化数据,灵活存储 |
💡 最佳实践
1. 表设计建议
sql
-- 主键设计:避免使用AUTO_INCREMENT导致热点
-- 推荐使用SHARD_ROW_ID_BITS分散热点
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT,
amount DECIMAL(10,2),
created_at TIMESTAMP
) SHARD_ROW_ID_BITS = 4;
-- 或使用UUID/雪花算法生成分散的主键
CREATE TABLE logs (
id VARCHAR(36) PRIMARY KEY, -- UUID
content TEXT,
created_at TIMESTAMP
);2. 索引优化
sql
-- 合理使用索引
CREATE INDEX idx_user_created ON orders(user_id, created_at);
-- 查看索引使用情况
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 123;
-- 强制使用索引
SELECT /*+ USE_INDEX(orders, idx_user_created) */
* FROM orders WHERE user_id = 123;3. 分区表使用
sql
-- Range分区
CREATE TABLE sales (
id BIGINT,
amount DECIMAL(10,2),
sale_date DATE
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);
-- Hash分区
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(50)
) PARTITION BY HASH(id) PARTITIONS 10;4. 混合负载处理
sql
-- OLTP查询走TiKV(行存)
SELECT * FROM orders WHERE id = 12345;
-- OLAP查询走TiFlash(列存)
SELECT /*+ READ_FROM_STORAGE(TIFLASH[orders]) */
DATE(created_at), SUM(amount)
FROM orders
WHERE created_at >= '2024-01-01'
GROUP BY DATE(created_at);🔧 性能调优
查询优化
sql
-- 查看执行计划
EXPLAIN SELECT * FROM orders WHERE user_id = 123;
-- 分析执行时间
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 123;
-- 查看慢查询
SELECT * FROM INFORMATION_SCHEMA.SLOW_QUERY
WHERE time > '2024-01-01'
ORDER BY query_time DESC
LIMIT 10;配置优化
sql
-- 调整并发参数
SET GLOBAL tidb_executor_concurrency = 8;
-- 调整内存限制
SET SESSION tidb_mem_quota_query = 8 << 30; -- 8GB
-- 优化器Hints
SELECT /*+ HASH_JOIN(t1, t2) */
t1.*, t2.*
FROM t1 JOIN t2 ON t1.id = t2.user_id;📈 适用场景
适合使用TiDB的场景
- 数据量大且持续增长: TB到PB级数据
- 需要水平扩展: 业务快速增长,数据量不可预测
- 强一致性要求: 金融、电商等对数据一致性要求高
- 复杂SQL查询: 需要Join、聚合等复杂分析
- HTAP混合负载: 同时需要OLTP和OLAP
- MySQL迁移: 现有MySQL应用需要扩展
不适合的场景
- 小数据量: 百万级以下数据,单机MySQL足够
- 极致读写性能: 纯KV场景,Redis等更合适
- 频繁DDL: TiDB的DDL相对较慢
- 复杂存储过程: 兼容性有限
🚀 快速开始
使用TiUP部署
bash
# 安装TiUP
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
# 启动测试集群
tiup playground
# 连接到TiDB
mysql -h 127.0.0.1 -P 4000 -u rootDocker部署
bash
# 使用Docker Compose
git clone https://github.com/pingcap/tidb-docker-compose.git
cd tidb-docker-compose
docker-compose up -d
# 连接
mysql -h 127.0.0.1 -P 4000 -u root📚 学习资源
🎯 面试重点
- 架构理解: TiDB的三层架构及各组件职责
- 分布式事务: Percolator事务模型
- Raft协议: Multi-Raft实现原理
- 性能优化: 热点问题、索引优化、SQL调优
- 与MySQL差异: 兼容性、功能差异
- HTAP能力: TiFlash的作用和使用场景