
5、日志
undo、redo、bin log
记录增删改,表结构变更
- undo log(回滚日志):是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。
- 在事务没有提交之前,会先记录更新前的数据到 undo log 日志中,回滚时,使用日志恢复;
- 插入时,记录数据的主键,回滚时直接删除这条记录
- 记录到
insert undo log,数据只对事务本身看到,当前事务提交后其他事务才能看见,因此事务提交后就能直接删除
- 记录到
- 删除时,记录数据的内容,回滚时把内容插入到表中
- 更新时,记录被更新列的旧址,回滚时把这些列更新为旧值
- 这两个记录到
update undo log,其他事务可能需要通过 MVCC 查询旧数据,提交后不能直接删除,会由purge线程进行删除
- 这两个记录到
- 放在 Buffer Pool 中的 Undo 页面
- redo log(重做日志):是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于掉电等故障恢复;
- 当数据增删改时,会先更新内存数据,并将修改以 redo log 的形式记录下来,这时才算完成
- 事务提交时,只要先将 redo log 持久化到磁盘即可,可以不需要等到将缓存在 Buffer Pool 里的脏页数据持久化到磁盘
- WAL(Write-Ahead Logging),先写日志,再写数据
- 因为日志顺序写入,数据随机写入,顺序写快很多
- redo log 不会直接落盘,会先写入到 redo log buffer,落盘时机:
- 正常关闭时
- 占用 buffer 的超过一半后
- InnoDB 的后台线程每隔 1 秒
- 配置后可以每次事务提交时,性能较差,可靠性强
- 0:每次提交只写入 redo log buffer
- 1:每次提交只写入 redo log buffer 并落盘
- 2:每次提交只写入 redo log buffer 并写入 page cache(内核落盘)
- 系统崩溃时, Mysql 重启后通过 redo log 恢复数据
- redo log 有两个日志文件,通过两个指针循环写的方式工作,落盘的脏页会让指针移动,表示有新的空间可用,如果写满了,MySQL 会被阻塞,执行脏页,之火正常运行,所以并发量大的系统,适当设置 redo log 的文件大小非常重要
- binlog(归档日志):是 Server 层生成的日志,主要用于数据备份和主从复制;
- 最开始只有这个日志,Innodb 引擎出来后,才有前两个,binlog 日志只能用于归档,因为记录了全量日志,无法确定哪些数据已经写入磁盘,哪些没有,不适用于 crash 恢复,适合删库恢复(redo log 只能崩溃恢复,无法删除全量恢复)
- 有三种格式:
- STATEMENT:记录原始 sql,但是如果 sql 中有动态函数,会导致数据不一致
- ROW:记录具体的数据,如果是批量修改,如 update 多行,会每一行都记录,量很大
- MIXED:会判定有无动态函数,如果有,采用 ROW,否则 STATEMENT,更加灵活
- binlog 是追加写(全量),redo log 是全量写
- 会先写入到 binlog cache,可以配置什么时候落盘:
- sync_binlog = 0:每次提交事务都只写入 page cache
- sync_binlog = 1:每次提交落盘(默认,但性能差)
- sync_binlog = N(N>1) :每次提交事务都只写入 page cache,N 个事务后落盘
- 每次 binlog 写入,都会触发 log dump 线程将日志发送给从库的(异步操作,一个从库一个 log dump 线程)
- 从库将日志写入 relay log,返回成功,之后单独的线程回放 relay log 的线程,将数据更新,实现主从一致
- 因为从库是串行写,两边速度可能不一致,通过 relay log 作为缓冲
- 也可以配置
- 同步复制,所有从库复制成功才算执行成功(性能差)
- 半同步复制,至少一个从库复制完成,保证至少一个从库数据完全一致
- 从库将日志写入 relay log,返回成功,之后单独的线程回放 relay log 的线程,将数据更新,实现主从一致
- redo log 记录了此次事务「完成后」的数据状态,undo log 记录了此次事务「开始前」的数据状态,这两个都是 Innodb 存储引擎生成的
更新具体流程:更新记录 1
- 查找记录 1:
- 如果 1 所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新;
- 否则将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 执行器记录后,确认前后数据是否一致:
- 如果一样的话就不进行后续更新流程;
- 如果不一样把更新前的后记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
- 开启事务
- 更新记录前,记录 undo log
- 更新记录,会先更新内存(同时标记为脏页)
- 将记录写到 redo log 里面
- 更新完成。
- 记录该语句对应的 binlog
- 事务提交,剩下的就是「两阶段提交」的事情了,接下来就讲这个。
为什么需要两阶段提交?
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。 导致主从数据不一致
- redo log 影响主库数据,binlog 影响从库数据
- 两者不一致,就会导致主从不一致
两阶段提交
- 分布式事务一致性协议,它可以保证多个逻辑操作要不全部成功,要不全部失败,不会出现半成功的状态。
- 由协调者和参与者共同完成,其中 binlog 作为协调者,存储引擎是参与者
- 将 redo log 的写入拆分成两个步骤,称为内部 XA 事务,外部的 XA 事务不需要了解
- 1、准备阶段:将 XID (内部 XA 事务的 ID)写入 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
- 提交阶段:
- 2、把 XID 写入到 binlog,然后将 binlog 刷新到磁盘,
- 3、接着调用引擎的提交事务接口,将 redo log 状态设置为 commit;
- 如果出现异常重启,无论 1 结束还是 2 结束崩溃,redo log 都处于 prepare 状态,在 MySQL 重启后会按顺序扫描 redo log 文件,碰到处于 prepare 状态的 redo log,就拿着 redo log 中的 XID 去 binlog 查看是否存在此 XID
- 如果 binlog 中没有当前内部 XA 事务的 XID,说明 redolog 完成刷盘,但是 binlog 还没有刷盘,则回滚事务。对应时刻 1 结束崩溃恢复的情况。
- 如果 binlog 中有当前内部 XA 事务的 XID,说明 redolog 和 binlog 都已经完成了刷盘,则提交事务。对应时刻 2 结束崩溃恢复的情况。
- 因为这个时候从库已经使用这个 binlog 进行主从复制了,所以主库也需要提交这个事务,否则就没办法主从一致了。
- 因此两阶段提交是以 binlog 写成功为事务提交成功的标识
- redo log 在事务未提交期间也会因为后台线程而落盘,但是这个时候 binlog 还没有落盘,所以如果这个时候 mysql 重启,会执行回滚,对应于 1 结束崩溃。
两阶段提交有什么问题?
两阶段提交虽然保证了两个日志文件的数据一致性,但是性能很差,主要有两个方面的影响:
- 磁盘 I/O 次数高:对于“双 1”配置,每个事务提交都会进行两次 fsync(刷盘),一次是 redo log 刷盘,另一次是 binlog 刷盘。
- 锁竞争激烈:两阶段提交虽然能够保证「单事务」两个日志的内容一致,但在「多事务」的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。
为什么两阶段提交的磁盘 I/O 次数会很高?
binlog 和 redo log 在内存中都对应的缓存空间,binlog 会缓存在 binlog cache,redo log 会缓存在 redo log buffer,它们持久化到磁盘的时机分别由下面这两个参数控制。一般我们为了避免日志丢失的风险,会将这两个参数设置为 1:
- 当 sync_binlog = 1 的时候,表示每次提交事务都会将 binlog cache 里的 binlog 直接持久到磁盘;
- 当 innodb_flush_log_at_trx_commit = 1 时,表示每次事务提交时,都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘;
可以看到,如果 sync_binlog 和 当 innodb_flush_log_at_trx_commit 都设置为 1,那么在每个事务提交过程中,都会至少调用 2 次刷盘操作,一次是 redo log 刷盘,一次是 binlog 落盘,所以这会成为性能瓶颈。
为什么锁竞争激烈?
在早期的 MySQL 版本中,通过使用 prepare_commit_mutex 锁来保证事务提交的顺序,在一个事务获取到锁时才能进入 prepare 阶段,一直到 commit 阶段结束才能释放锁,下个事务才可以继续进行 prepare 操作。
通过加锁虽然完美地解决了顺序一致性的问题,但在并发量较大的时候,就会导致对锁的争用,性能不佳。
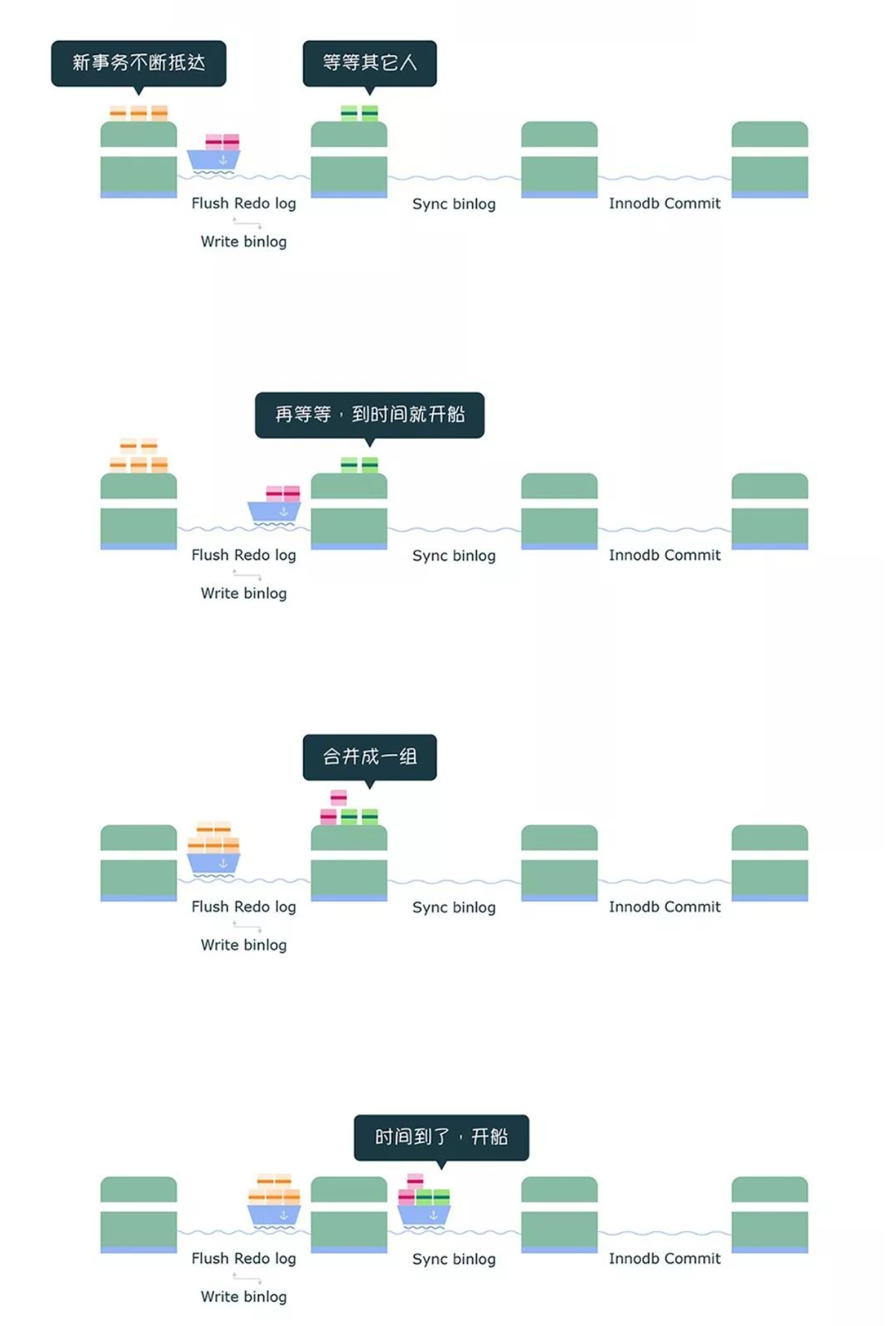
组提交
MySQL 引入了 binlog 组提交(group commit)机制,当有多个事务提交的时候,会将多个 binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数,如果说 10 个事务依次排队刷盘的时间成本是 10,那么将这 10 个事务一次性一起刷盘的时间成本则近似于 1。
引入了组提交机制后,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个过程:
- flush 阶段:多个事务按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
- sync 阶段:对 binlog 文件做 fsync 操作(多个事务的 binlog 合并一次刷盘);
- commit 阶段:各个事务按顺序做 InnoDB commit 操作;
上面的每个阶段都有一个队列,每个阶段有锁进行保护,因此保证了事务写入的顺序,第一个进入队列的事务会成为 leader,leader 领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
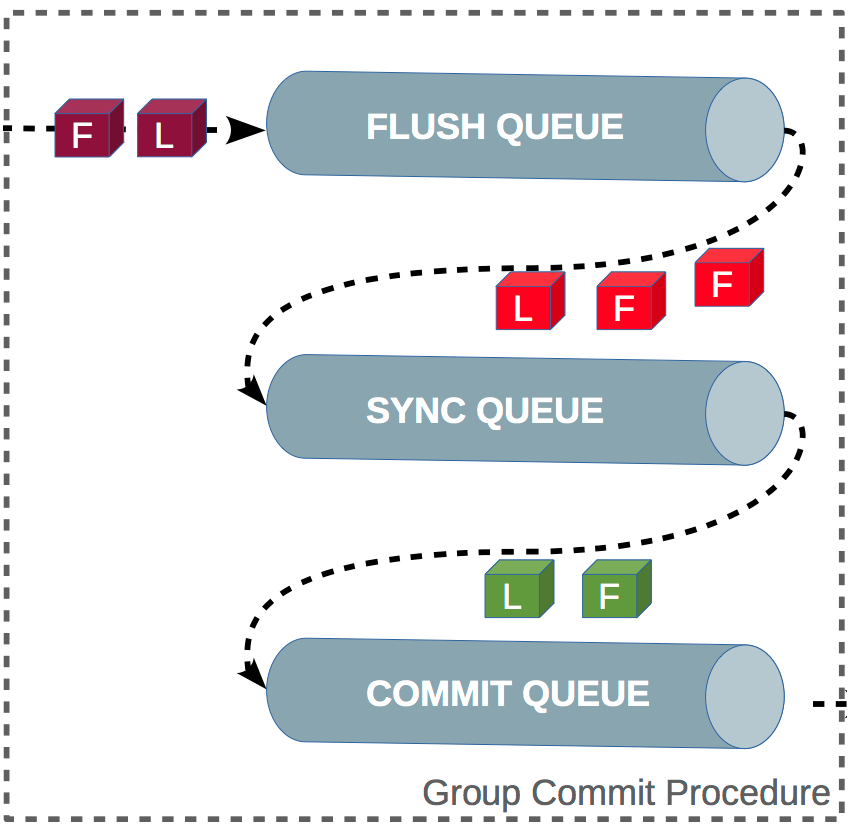
对每个阶段引入了队列后,锁就只针对每个队列进行保护,不再锁住提交事务的整个过程,可以看的出来,锁粒度减小了,这样就使得多个阶段可以并发执行,从而提升效率。
有 binlog 组提交,那有 redo log 组提交吗?
这个要看 MySQL 版本,MySQL 5.6 没有 redo log 组提交,MySQL 5.7 有 redo log 组提交。
在 MySQL 5.6 的组提交逻辑中,每个事务各自执行 prepare 阶段,也就是各自将 redo log 刷盘,这样就没办法对 redo log 进行组提交。
所以在 MySQL 5.7 版本中,做了个改进,在 prepare 阶段不再让事务各自执行 redo log 刷盘操作,而是推迟到组提交的 flush 阶段,也就是说 prepare 阶段融合在了 flush 阶段。
这个优化是将 redo log 的刷盘延迟到了 flush 阶段之中,sync 阶段之前。通过延迟写 redo log 的方式,为 redolog 做了一次组写入,这样 binlog 和 redo log 都进行了优化。
接下来介绍每个阶段的过程,注意下面的过程针对的是“双 1”配置(sync_binlog 和 innodb_flush_log_at_trx_commit 都配置为 1)。
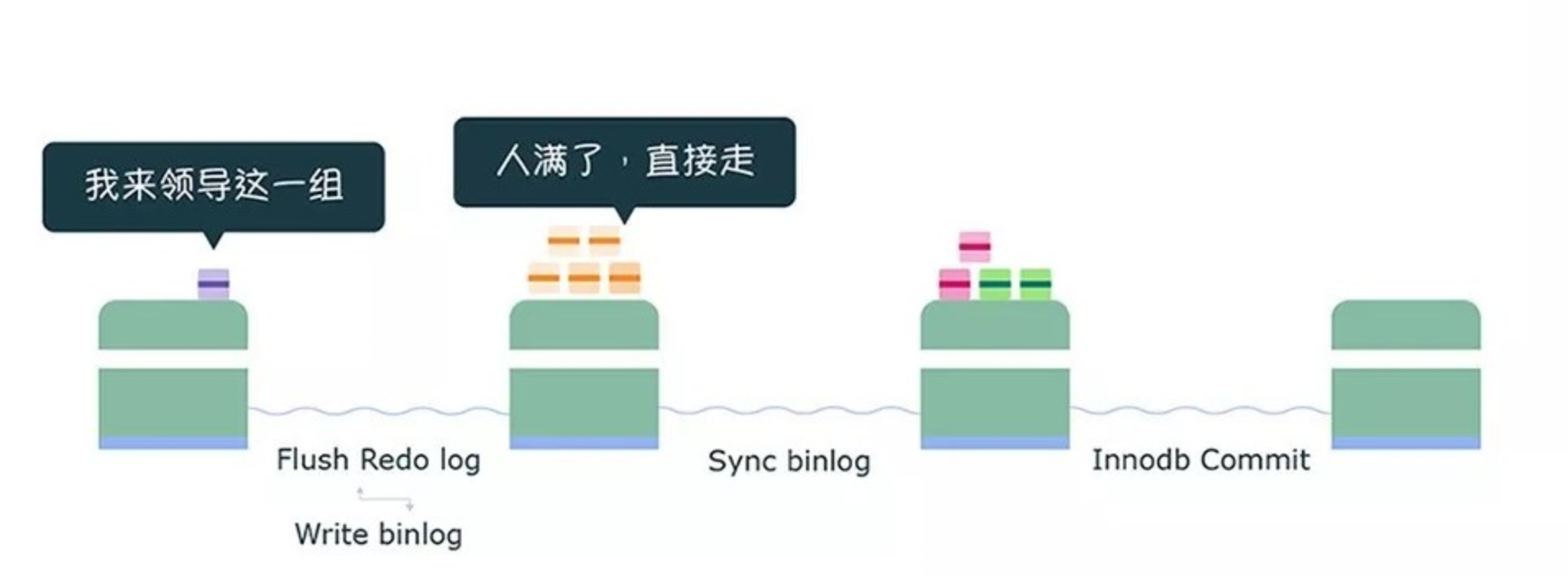
flush 阶段
第一个事务会成为 flush 阶段的 Leader,此时后面到来的事务都是 Follower:
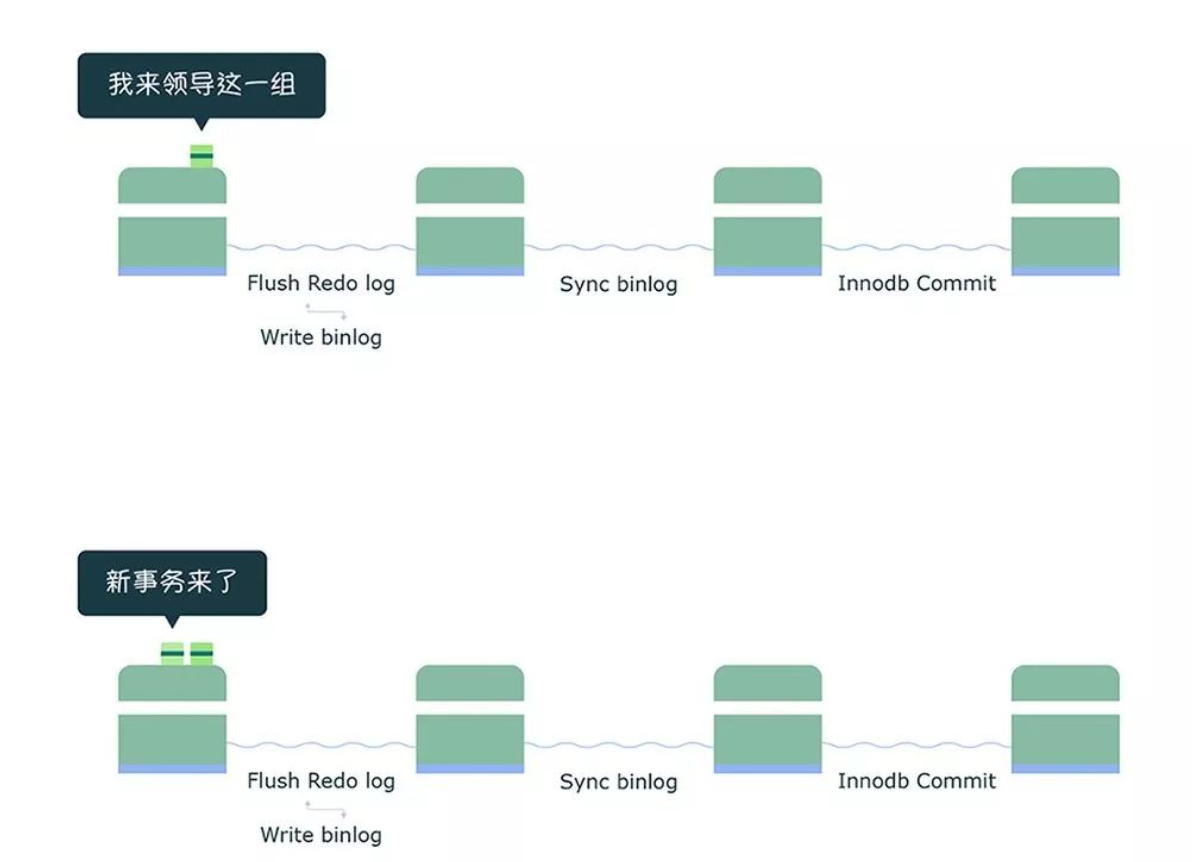
接着,获取队列中的事务组,由绿色事务组的 Leader 对 rodo log 做一次 write + fsync,即一次将同组事务的 redolog 刷盘:
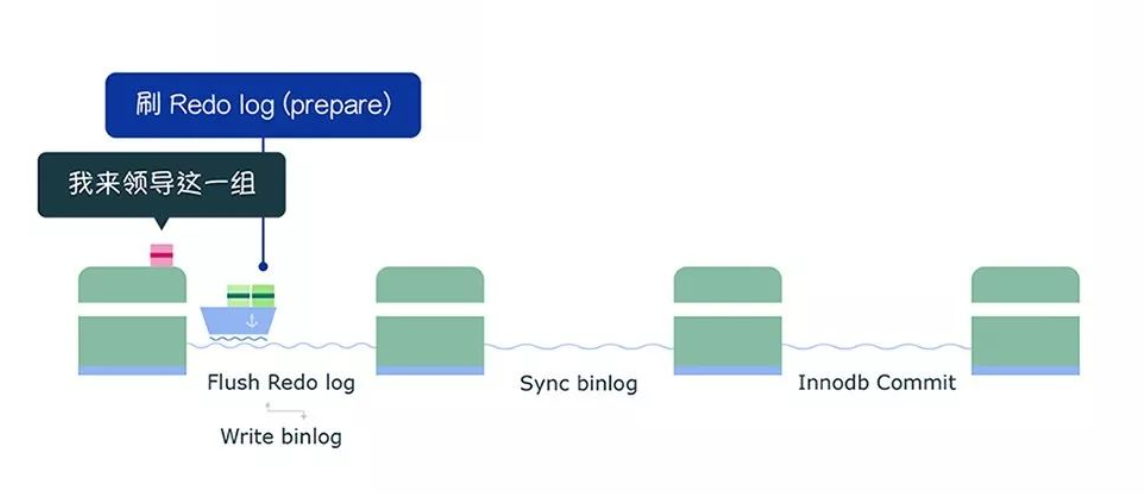
完成了 prepare 阶段后,将绿色这一组事务执行过程中产生的 binlog 写入 binlog 文件(调用 write,不会调用 fsync,所以不会刷盘,binlog 缓存在操作系统的文件系统中)。
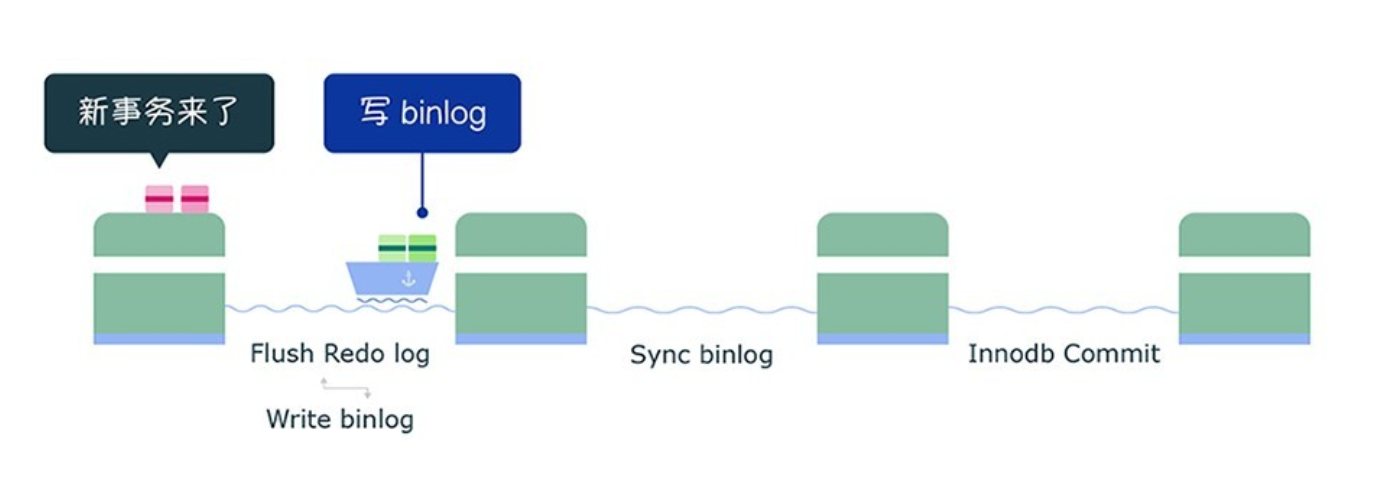
从上面这个过程,可以知道 flush 阶段队列的作用是用于支撑 redo log 的组提交。
如果在这一步完成后数据库崩溃,由于 binlog 中没有该组事务的记录,所以 MySQL 会在重启后回滚该组事务。
sync 阶段
绿色这一组事务的 binlog 写入到 binlog 文件后,并不会马上执行刷盘的操作,而是会等待一段时间,这个等待的时长由 Binlog_group_commit_sync_delay 参数控制,目的是为了组合更多事务的 binlog,然后再一起刷盘,如下过程:
不过,在等待的过程中,如果事务的数量提前达到了 Binlog_group_commit_sync_no_delay_count 参数设置的值,就不用继续等待了,就马上将 binlog 刷盘,如下图:
从上面的过程,可以知道 sync 阶段队列的作用是用于支持 binlog 的组提交。
如果想提升 binlog 组提交的效果,可以通过设置下面这两个参数来实现:
binlog_group_commit_sync_delay= N,表示在等待 N 微妙后,直接调用 fsync,将处于文件系统中 page cache 中的 binlog 刷盘,也就是将「binlog 文件」持久化到磁盘。binlog_group_commit_sync_no_delay_count = N,表示如果队列中的事务数达到 N 个,就忽视 binlog_group_commit_sync_delay 的设置,直接调用 fsync,将处于文件系统中 page cache 中的 binlog 刷盘。
如果在这一步完成后数据库崩溃,由于 binlog 中已经有了事务记录,MySQL 会在重启后通过 redo log 刷盘的数据继续进行事务的提交。
commit 阶段
最后进入 commit 阶段,调用引擎的提交事务接口,将 redo log 状态设置为 commit。
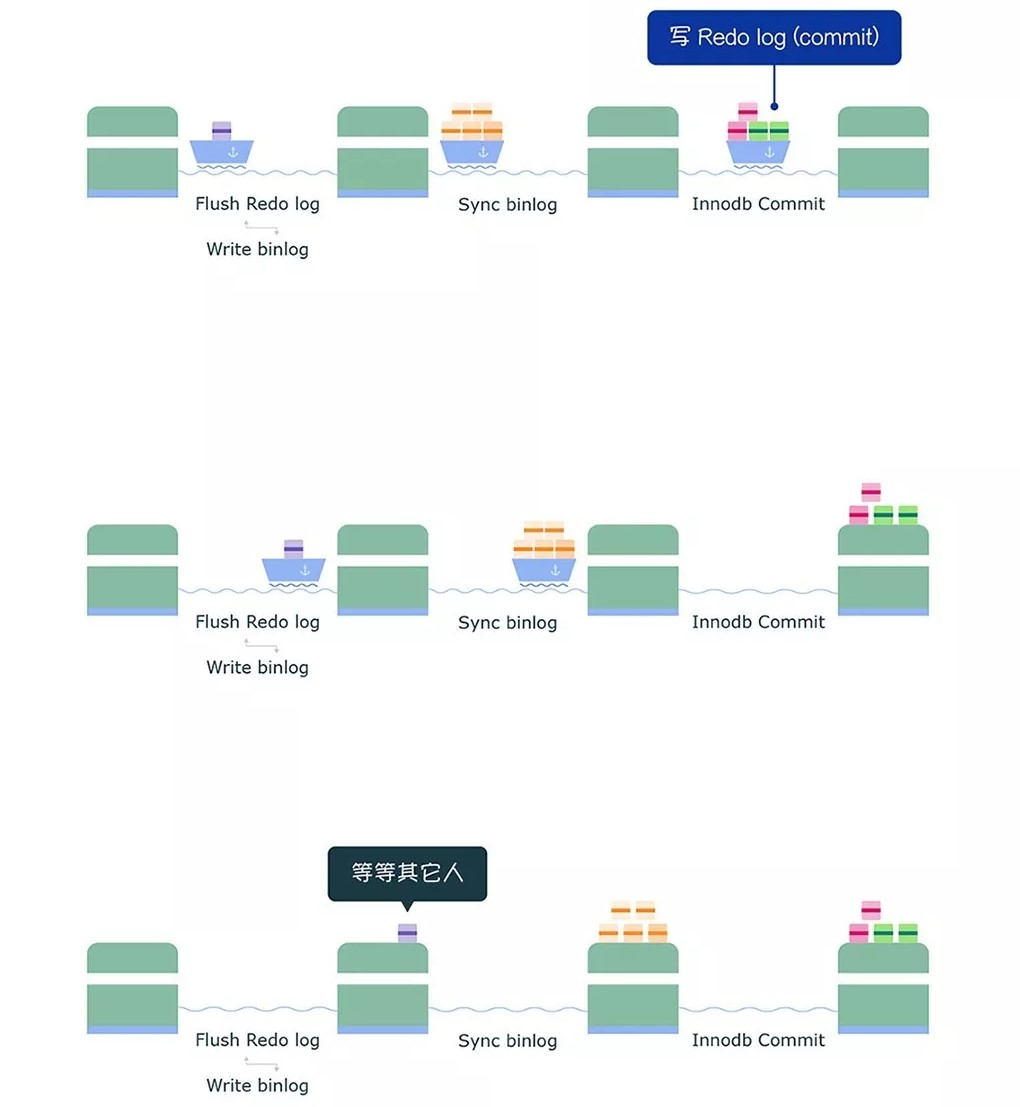
commit 阶段队列的作用是承接 sync 阶段的事务,完成最后的引擎提交,使得 sync 可以尽早的处理下一组事务,最大化组提交的效率。
MySQL 磁盘 I/O 很高,有什么优化的方法?
现在我们知道事务在提交的时候,需要将 binlog 和 redo log 持久化到磁盘,那么如果出现 MySQL 磁盘 I/O 很高的现象,我们可以通过控制以下参数,来“延迟”binlog 和 redo log 刷盘的时机,从而降低磁盘 I/O 的频率:
- 设置组提交的两个参数:binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数,延迟 binlog 刷盘的时机,从而减少 binlog 的刷盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但即使 MySQL 进程中途挂了,也没有丢失数据的风险,因为 binlog 早被写入到 page cache 了,只要系统没有宕机,缓存在 page cache 里的 binlog 就会被持久化到磁盘。
- 将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000),表示每次提交事务都 write,但累积 N 个事务后才 fsync,相当于延迟了 binlog 刷盘的时机。但是这样做的风险是,主机掉电时会丢 N 个事务的 binlog 日志。
- 将 innodb_flush_log_at_trx_commit 设置为 2。表示每次事务提交时,都只是缓存在 redo log buffer 里的 redo log 写到 redo log 文件,注意写入到「redo log 文件」并不意味着写入到了磁盘,因为操作系统的文件系统中有个 Page Cache,专门用来缓存文件数据的,所以写入「redo log 文件」意味着写入到了操作系统的文件缓存,然后交由操作系统控制持久化到磁盘的时机。但是这样做的风险是,主机掉电的时候会丢数据。
总结
具体更新一条记录 UPDATE t_user SET name = 'xiaolin' WHERE id = 1; 的流程如下:
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id = 1 这一行记录:
- 如果 id=1 这一行所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新;
- 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
- 如果一样的话就不进行后续更新流程;
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
- 开启事务,InnoDB 层更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面,不过在内存修改该 Undo 页面后,需要记录对应的 redo log。
- InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘 I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上。
- 至此,一条记录更新完了。
- 在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘。
- 事务提交(为了方便说明,这里不说组提交的过程,只说两阶段提交):
- prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
- commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件);
- 至此,一条更新语句执行完成。
参考资料:
- 《MySQL 45 讲》
- 《MySQL 是怎样运行的?》
- https://developer.aliyun.com/article/617776
- http://mysql.taobao.org/monthly/2021/10/01/
- https://www.cnblogs.com/Neeo/articles/13883976.html
- https://www.cnblogs.com/mengxinJ/p/14211427.html
错误日志、查询日志、慢查询日志
# 开启慢查询日志功能
SET GLOBAL slow_query_log = 'ON';
# 慢查询日志存放位置
SET GLOBAL slow_query_log_file = '/var/lib/mysql/ranking-list-slow.log';
# 无论是否超时,未被索引的记录也会记录下来。
SET GLOBAL log_queries_not_using_indexes = 'ON';
# 慢查询阈值(秒),SQL 执行超过这个阈值将被记录在日志中。
SET SESSION long_query_time = 1;
# 慢查询仅记录扫描行数大于此参数的 SQL
SET SESSION min_examined_row_limit = 100;设置成功之后,使用 show variables like 'slow%'; 命令进行查看。
| Variable_name | Value |
+---------------------+--------------------------------------+
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/ranking-list-slow.log |
+---------------------+--------------------------------------+
3 rows in set (0.01 sec)我们故意在百万数据量的表(未使用索引)中执行一条排序的语句:
SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;确保自己有对应目录的访问权限:
chmod 755 /var/lib/mysql/查看对应的慢查询日志:
cat /var/lib/mysql/ranking-list-slow.log我们刚刚故意执行的 SQL 语句已经被慢查询日志记录了下来:
# Time: 2022-10-09T08:55:37.486797Z
# User@Host: root[root] @ [172.17.0.1] Id: 14
# Query_time: 0.978054 Lock_time: 0.000164 Rows_sent: 999999 Rows_examined: 1999998
SET timestamp=1665305736;
SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;这里对日志中的一些信息进行说明:
Time:被日志记录的代码在服务器上的运行时间。User@Host:谁执行的这段代码。Query_time:这段代码运行时长。Lock_time:执行这段代码时,锁定了多久。Rows_sent:慢查询返回的记录。Rows_examined:慢查询扫描过的行数。
实际项目中,慢查询日志通常会比较复杂,我们需要借助一些工具对其进行分析。像 MySQL 内置的 mysqldumpslow 工具就可以把相同的 SQL 归为一类,并统计出归类项的执行次数和每次执行的耗时等一系列对应的情况。
找到了慢 SQL 之后,我们可以通过 EXPLAIN 命令分析对应的 SELECT 语句:
mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)比较重要的字段说明:
select_type:查询的类型,常用的取值有 SIMPLE(普通查询,即没有联合查询、子查询)、PRIMARY(主查询)、UNION(UNION 中后面的查询)、SUBQUERY(子查询)等。table:表示查询涉及的表或衍生表。type:执行方式,判断查询是否高效的重要参考指标,结果值从差到好依次是:ALL < index < range ~ index_merge < ref < eq_ref < const < system。rows: SQL 要查找到结果集需要扫描读取的数据行数,原则上 rows 越少越好。- ......
关于 Explain 的详细介绍,请看这篇文章:MySQL 执行计划分析[1]。另外,再推荐一下阿里的这篇文章:慢 SQL 治理经验总结,总结的挺不错。