
3.1 HTTP 常见面试题
HTTP 基本概念
HTTP 常见的状态码有哪些?
1xx:提示信息,处理中的一种中间状态。- 101:协议切换(Switching Protocols),服务器已经理解了客户端的请求,并将通过 Upgrade 消息头通知客户端采用不同的协议来完成这个请求。比如切换到一个实时且同步的协议(如 WebSocket)以传送利用此类特性的资源。
2xx:服务器成功处理请求。- 「200 OK」通用成功码,可以有body。
- 「201 Created」请求成功并且创建了一个新的资源。
- 「204 No Content」不带body的200。
- 「206 Partial Content」分块下载等表示返回的 body 数据只是一部分。HTTP/1.1 之后才有
3xx:资源发生了变动,需要客户端重定向(请求新的URL)。- 「301 Moved Permanently」永久重定向,请求的资源不存在了。
- 「302 Found」临时重定向,资源还在,暂时用另一个 URL 来访问。
- 会在响应头里使用字段
Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 会在响应头里使用字段
- 「304 Not Modified」资源未修改,重定向已存在的缓冲文件。
4xx:服务器无法处理请求,也就是错误码的含义。- 「400 Bad Request」通用错误码。
- 「401 Unauthorized」未认证。
- 「403 Forbidden」:服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」:表示请求的资源在服务器上不存在或未找到。
- 405 请求方法不对
5xx:服务器处理时内部发生了错误,属于服务器端的错误码。- 「500 Internal Server Error」通用错误码。
- 「501 Not Implemented」表示客户端请求的功能还不支持。
- 「502 Bad Gateway」服务器是网关或代理自身工作正常,访问后端服务器发生了错误。
- 如后端服务崩溃,nginx 无法正常收到服务器的响应
- 「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端。
- 「504 Gateway Timeout」后端服务处理时间过长,超过了网关的超时时间。
GET 与 POST
GET 和 POST 有什么区别?
「幂等」:多次执行相同的操作,结果都是「相同」的。
主要区别是语义
- GET 请求的参数位置一般是写在 URL 中
- 只允许 ASCII 字符(非ASCII需要编码转换)
- 浏览器对 URL 长度会有限制。
- 语义:获取或查询资源,不会修改资源。
- 因此是幂等,浏览器可以缓存。Get 请求可以保存为书签
- POST 请求携带数据的位置一般是写在报文 body 中
- 格式、大小不限制。
- 语义:创建或修改资源
- 不幂等,每次请求数据不一定相同,浏览器一般不会缓存,且不能将 Post 请求存为书签
- 但是 GET 也能在 body 中携带数据,POST 也能在 URL 中携带数据,但是兼容性可能一般。
HTTP1.1默认长连接,1.0默认短连接。
HTTP 与 HTTPS
- HTTP 是明文传输,有安全风险。HTTPS 在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,加密传输。但是响应的 HTTPS 消耗性能更高。
- HTTP 连接建立相对简单,TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
- HTTP 的 URL 前缀是
http://,HTTPS 的 URL 前缀是https://。 - SEO(搜索引擎优化)一般会更加青睐使用 HTTPS 协议的网站,因为可以保护用户隐私。
HTTPS
- 混合加密:通信建立前采用非对称加密交换「会话秘钥」,通信过程使用对称加密加密明文数据
- 摘要算法:为数据内容计算哈希,实现完整性,校验机制解决了篡改风险。
- 身份证书:将服务器公钥放入到数字证书中,解决了冒充的风险。 2. 摘要算法 + 数字签名
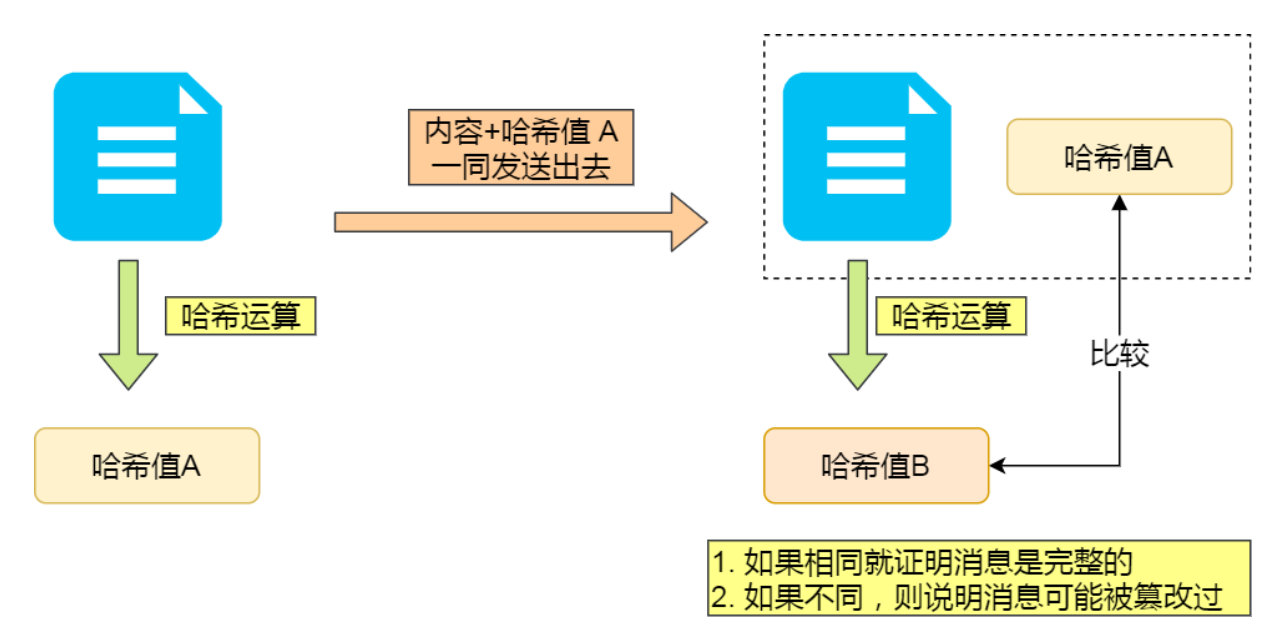
但是中间人能将内容和哈希值一同修改(传输假的数据)。用非对称加密算法来解决,共有两个密钥:
HTTPS 是如何建立连接的?其间交互了什么?
SSL 指安全套接字协议(Secure Sockets Layer),TLS 是基于 SSL 之上的,SSL/TLS是习惯称法。
SSL/TLS 协议基本流程:
- TLS四次握手(不同算法不一样)
- 双方采用「会话秘钥」进行加密通信。
RSA算法的TLS 协议建立的详细流程:
- ClientHello:客户端发送加密通信请求
- 客户端支持的 TLS 协议版本
- 客户端随机数
- 客户端支持的密码套件(如 RSA 算法)
- SeverHello:服务器收到后回应
- 确认 TLS 协议版本,支持继续握手,不支持直接关闭。
- 服务器随机数
- 确认密码套件
- 服务器的 CA
- 客户端回应:
- 通过浏览器或操作系统确认服务器 CA 的真实性,真实就继续
- 从 CA 中取出服务器公钥,通过协商的加密算法加密以下内容并发送
- 一个随机数(这个随机数不会被捕获到,因为只有服务器的私钥可以解开,如果泄露,那么数据就会被盗取)
- 后续使用会话密钥加密通信的通知
- 握手结束的通知,并把之前的内容做摘要,供服务器校验。
- 服务器回应:
- 通过协商的加密算法以及前面的三个随机数,计算出本次通信的「会话秘钥」
- 发送使用会话密钥通知
- 握手结束通知,并把前面的数据做摘要,供客户端校验
- 后续两端完全使用会话密钥进行加密通信。
CA 签发证书的过程:
- 首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
- 然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
- 最后将 Certificate Signature 添加在文件证书上,形成数字证书;
客户端校验服务端的数字证书的过程:
- 首先客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
- 通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2;
- 最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
证书的验证过程中还存在一个证书信任链的问题,因为我们向 CA 申请的证书一般不是根证书签发的,而是由中间证书签发的,中间证书是根证书签发的。为了将根证书隔离,否则根证书失守,影响面很大。 根证书信任中间证书,中间证书信任服务器证书,那么服务器证书就会被信任。构成了一条信任链路
HTTPS 一定安全可靠吗?
HTTPS 是有中间人攻击的
- 如果建立连接时套了一层中间人,那么其实用户只是和中间人加密了,中间人和服务器加密了,那么用户和服务器通信的所有数据,中间人都能轻易获取
- 但是需要建立连接时,用户信任了中间人的证书,否则连接是无法建立的
- 如果不信任,浏览器会识别其非法,告知用户
- 如果用户坚持点击继续浏览,那么就接受了中间人伪造的证书了(需要避免)
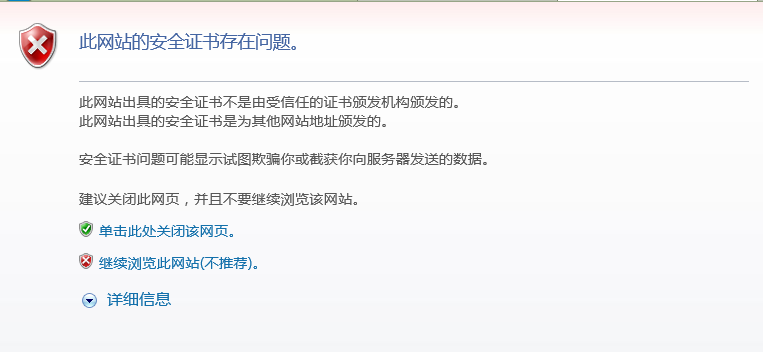
- 如果用户坚持点击继续浏览,那么就接受了中间人伪造的证书了(需要避免)
- 抓包工具抓取 HTTPS 明文数据原理和中间人一致,想要获取浏览器信任,那么只能通过一下方式,抓包工具只能通过第三种,因此在启动抓包工具时,会生成根证书,并要求用户导入系统中,
- 去网站服务端拿到私钥;
- 去 CA 处拿域名签发私钥;
- 自己签发受浏览器信任的证书;
跨域
刚刚提到了一个词叫跨域,那什么是跨域呢?在了解跨域之前,首先要了解一个概念**:同源**。所谓同源是指,域名、协议、端口均相同。

不明白没关系,举个例子。

需要特别注意的是,localhost 和 127.0.0.1 虽然都指向本机,但也不属于同源。
而非同源之间网页调用就是我们所说的跨域。在浏览器同源策略限制下,向不同源发送 XHR 请求,浏览器认为该请求不受信任,禁止请求,具体表现为请求后不正常响应。
URL和URI
- URL:Uniform Resource Locator 统一资源定位符;
协议://域名:端口/虚拟目录/文件名
- URI: Uniform Resource Identifier 统一资源标识符;
其实一直有个误解,很多人以为 URI 是 URL 的子集,其实应该反过来。URL 是 URI 的子集才对。简单解释下。 假设"小白"(URI)是一种资源,而"在迪丽亦巴的怀里"表明了一个位置。如果你想要找到(locate)小白,那么你可以到"在迪丽亦巴怀里"找到小白,而"在迪丽亦巴怀里的/小白"才是我们常说的 URL。而"在迪丽亦巴怀里的/小白"(URL)显然是"小白"(URI)的子集,毕竟,"小白"还可能是"在牛亦菲怀里的/小白"(其他 URL)。