微服务架构:
将应用程序拆分为小而自治的服务的软件架构模式。每个服务专注于执行特定的业务功能,并通过轻量级的通信机制进行交互。
每个服务有自己的代码库、数据库等,可以有不同的技术栈
优势
- 独立开发和部署
- 松耦合:服务间通过网络通信,单个服务可以轻松更换和升级组件
- 高可扩展性:实例扩缩容简单
- 技术多样性:选择合适的技术栈
- 弹性和容错性:一个服务故障,其他服务还能使用
- 敏捷开发:任何功能都可以快速开发
劣势:
- 复杂度高:需要服务发现、负载均衡、监控和日志等基础设施
- 分布式挑战:如网络延迟、一致性、事务管理等
- 通信开销:不同服务间通信有开销和时延
- 排查问题:出错后由于链路长,排查较为困难
SOA 和微服务架构
组件:
- 微服务:单体功能
- 服务通信:RPC、HTTP 等
- 服务发现:
- 注册:IP、端口
- 发现:
- 健康检查:定期检测
- 负载均衡
- 动态更新:
- 故障转移:
- 熔断:
- 打开:当依赖服务频繁失败,会暂停请求
- 半打开:过一段时间开始尝试少量请求,探测服务是否恢复
- 关闭:半打开请求都成功,恢复正常调用
- 降级:在服务熔断或报错时,使用兜底方案(比如返回默认值)
- 熔断:
- 流量控制:
- 限流:
- goo 中有
golang.org/x/time/rate库
- goo 中有
- 限流:
- 监控和日志:
- 部署和扩展:CICD
耦合:组件之间依赖关系强度的度量被认为是耦合。一个好的设计总是被认为具有高内聚力和低耦合性。
QPS(Queries Per Second):每秒查询数
- 获取方案:
- promethues counter 打点
- 计算方式:
QPS = (cnt(t) - cnt(t - Δt)) / Δt- 一般会将每一个时间段的计数放入数组(数组每个元素称为 bucket),比如每 1 的数据,粒度越细,服务治理越好,但是成本越高
- 一般内存数组是环形数组,过期的落库
- 那么一段时间的 QPS 就可以对这段时间内的 bucket 值求和获得
- 平均耗时:用一个额外的 bucket 存放这个时间段内的总耗时(类似于一行两列数组)
- 平均耗时:
Latency总和/cnt总和 - 可以使用
sentinel-golang组件实现
- 平均耗时:
- 常见场景 QPS
- 多模态推理:小于 100
- 文本推理:小于 400
- 写数据库:小于 5k
- 读数据库:小于 10k
- 读缓存:大于 10k
- 获取方案:
参考 Nagle 算法的做法
我们熟悉的 TCP 协议里,有个算法叫 Nagle 算法,设计它的目的,就是为了避免一次传过少数据,提高数据包的有效数据负载。
当我们想要发送一些数据包时,数据包会被放入到一个缓冲区中,不立刻发送,那什么时候会发送呢?
数据包会在以下两个情况被发送:
- 缓冲区的数据包长度达到某个长度(MSS)时。
- 或者等待超时(一般为
200ms)。在超时之前,来的那么多个数据包,就是凑不齐 MSS 长度,现在超时了,不等了,立即发送。
这个思路就非常值得我们参考。我们完全可以自己在代码层实现一波,实现也非常简单。
1.我们定义一个带锁的全局队列(链表)。
2.当上游服务输入一个视频和它对应的 N 张图片时,就加锁将这 N 张图片数据和一个用来存放返回结果的结构体放入到全局队列中。然后死循环读这个结构体,直到它有结果。就有点像阻塞等待了。
3.同时在服务启动时就起一个线程 A专门用于收集这个全局队列的图片数据。线程 A负责发起调用下游服务的请求,但只有在下面两个情况下会发起请求
当收集的图片数量达到 xx 张的时候
距离上次发起请求过了 xx 毫秒(超时)
4.调用下游结束后,再根据一开始传入的数据,将调用结果拆开来,送回到刚刚提到的用于存放结果的结构体中。
5.第 2 步里的死循环因为存放返回结果的结构体,有值了,就可以跳出死循环,继续执行后面的逻辑。
.png)
这就像公交车站一样,公交车站不可能每来一个顾客就发一辆公交车,当然是希望车里顾客越多越好。上游每来一个请求,就把请求里的图片,也就是乘客,塞到公交车里,公交车要么到点发车(向下游服务发起请求),要么车满了,也没必要等了,直接发车。这样就保证了每次发车的时候公交车里的顾客数量足够多,发车的次数尽量少。
大体思路就跟上面一样,如果是用 go 来实现的话,就会更加简单。
比如第 1 步里的加锁全局队列可以改成有缓冲长度的 channel。第 2 步里的"用来存放结果的结构体",也可以改成另一个无缓冲 channel。执行 res := <-ch, 就可以做到阻塞等待的效果。
而核心的仿 Nagle 的代码也大概长下面这样。当然不看也没关系,反正你已经知道思路了。
func CallAPI() error {
size := 100
// 这个数组用于收集视频里的图片,每个 IVideoInfo 下都有N张图片
videoInfos := make([]IVideoInfo, 0, size)
// 设置一个200ms定时器
tick := time.NewTicker(200 * time.Microsecond)
defer tick.Stop()
// 死循环
for {
select {
// 由于定时器,每200ms,都会执行到这一行
case <-tick.C:
if len(videoInfos) > 0 {
// 200ms超时,去请求下游
limitStartFunc(videoInfos, true)
// 请求结束后把之前收集的数据清空,重新开始收集。
videoInfos = make([]IVideoInfo, 0, size)
}
// AddChan就是所谓的全局队列
case videoInfo, ok := <-AddChan:
if !ok {
// 通道关闭时,如果还有数据没有去发起请求,就请求一波下游服务
limitStartFunc(videoInfos, false)
videoInfos = make([]IVideoInfo, 0, size)
return nil
} else {
videoInfos = append(videoInfos, videoInfo)
if videoInfos 内的图片满足xx数量 {
limitStartFunc(videoInfos, false)
videoInfos = make([]IVideoInfo, 0, size)
// 重置定时器
tick.Reset(200 * time.Microsecond)
}
}
}
}
return nil
}通过这一操作,上游每来一个请求,都会将视频里的图片收集起来,堆到一定张数的时候再统一请求,大大提升了每次 batch call 的图片数量,同时也减少了调用下游服务的次数。真·一举两得。
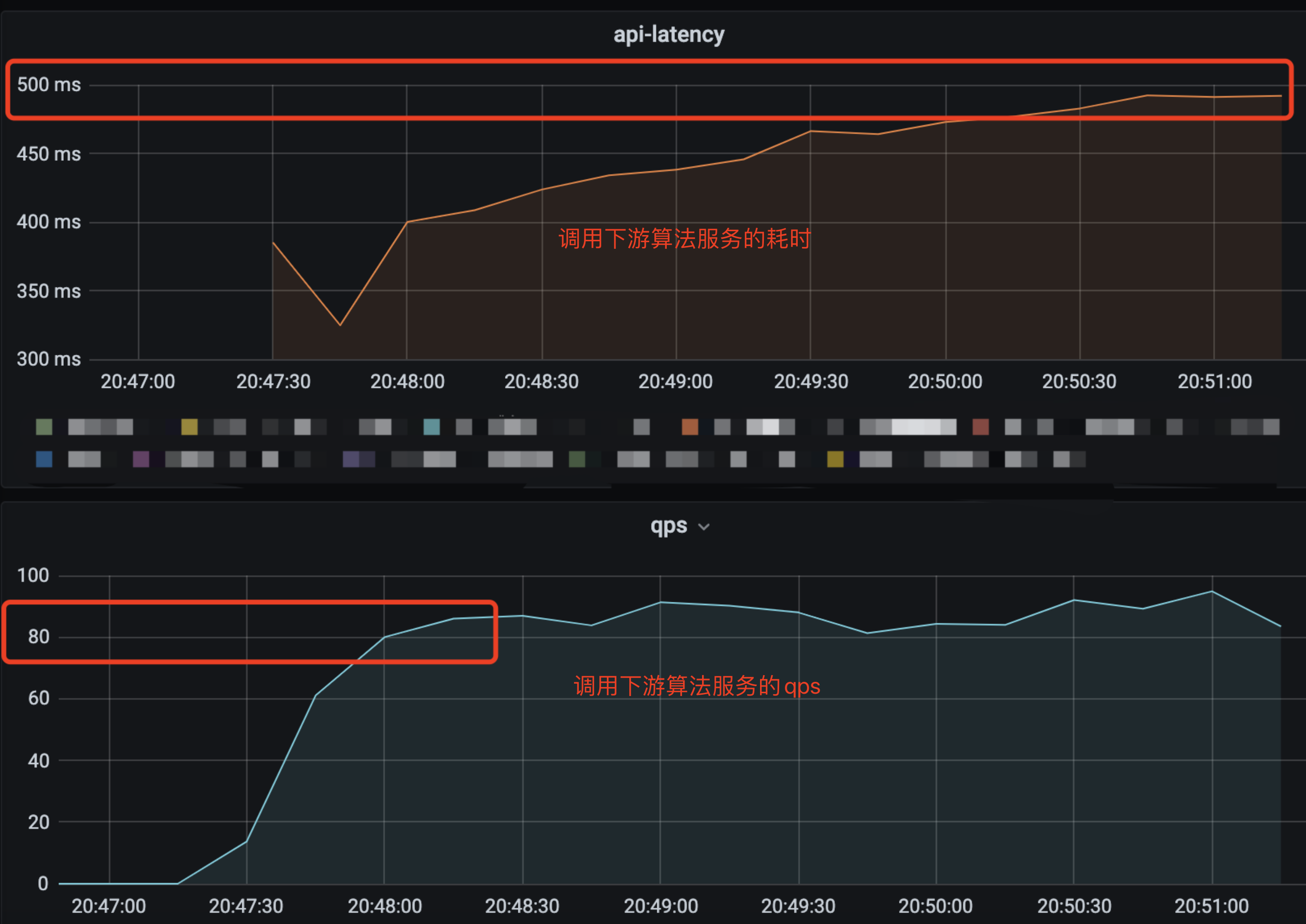
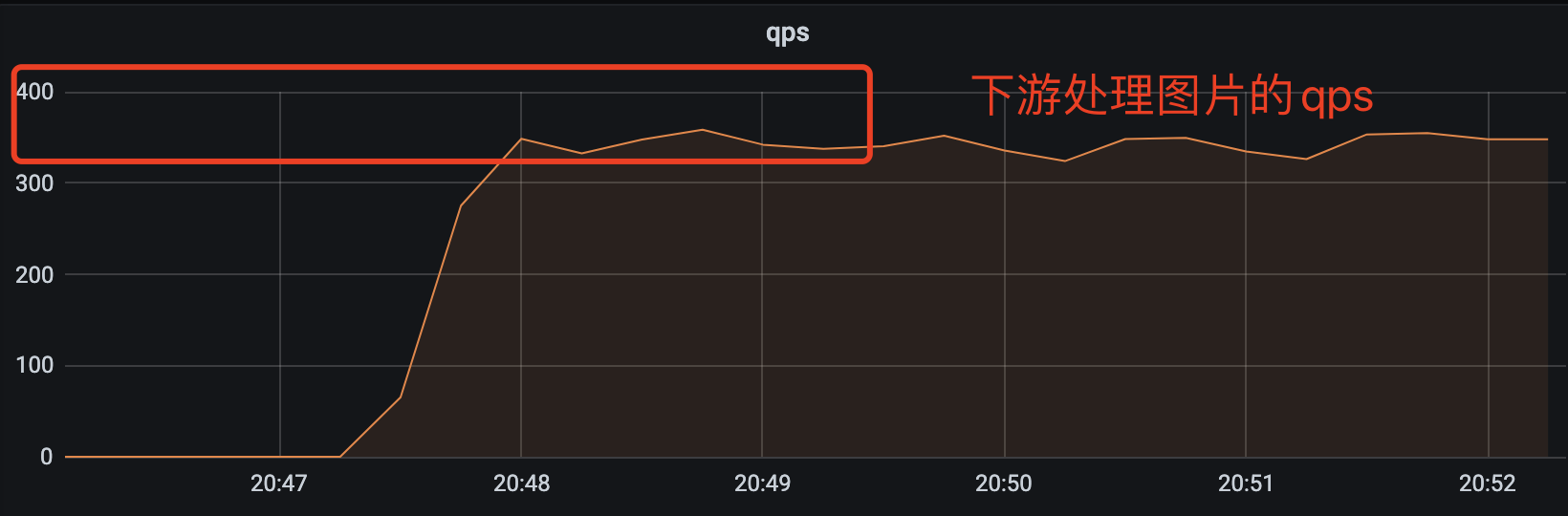
优化的效果也比较明显,上游服务支持的 qps 从原来不稳定的 3q~15q 变成稳定的 90q。下游的接口耗时也变得稳定多了,从原来的过山车似的飙到 15s 变成稳定的 500ms 左右。处理的图片的速度也从原来 20qps 提升到 350qps。
到这里就已经大大超过业务需求的预期(40qps)了,够用就好,多一个 qps 都是浪费。
可以了,下班吧。